Opus – Polling App
Tools:Node.js • Docker • Nginx • Redis
Skills:Backend Engineer • DevOps Engineer
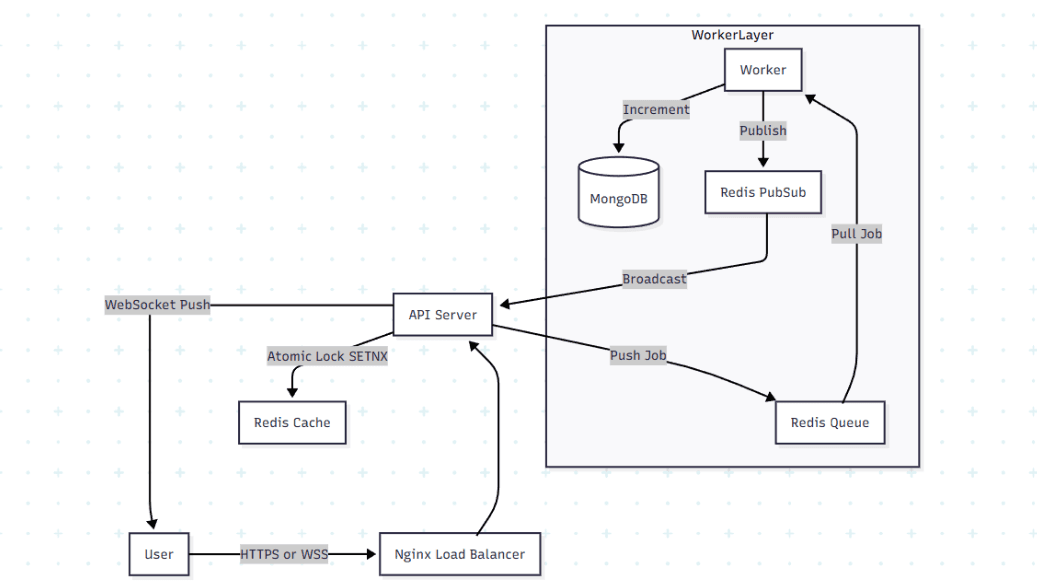
How I built a distributed polling system that handles thundering herd scenarios with sub-50ms latency
What Made This Hard
Millions of records, sub-second queries The web scraper pulls roughly 10,000 articles daily. With millions of historical records in the database, users still expect instant search results and complex filtering. The database alone couldn't deliver that performance
Complex visualizations over massive datasets Corporate innovation teams need charts showing technology trends, patent landscapes, and competitive intelligence. Each visualization aggregates thousands or millions of data points while staying interactive
How I Built It
The key was a multi-layer caching strategy. Redis stores pre-aggregated statistics, frequently accessed datasets, and query results. When users search or filter, the system checks Redis first before hitting the main database. Query times dropped from seconds to milliseconds
I also implemented background workers using queues to process complex aggregations asynchronously, ensuring the main thread is never blocked
Tech Stack
Frontend: Next.js, TailwindCSS, TypeScript
Backend: Node.js, Express
Database: PostgreSQL, Redis
Deployment: Docker, AWS, Nginx
Links
More Projects

FinLedger
A high-integrity, ACID-compliant double-entry ledger system designed for transactional idempotency and financial auditability
Read Story →
KeyVaultX
A secure secret management backend with AES-256 encryption and hybrid auth
Read Story →
AvoidEsse
An end-to-end disease surveillance system integrating real-time data ingestion with ML for outbreak prediction
Read Story →